How Hadoop Works Internally
- Mister siswa
- 2022 November 25T10:04
- Hadoop
An open source software platform called Apache Hadoop stores data in a distributed fashion and processes it concurrently. Hadoop offers the most dependable batch processing engine, MapReduce, as well as the most trustworthy storage layer, HDFS, and resource management layer, YARN. In this lesson on "How Hadoop works internally," we will learn what Hadoop is, how it functions, its many parts, daemons, the functions of HDFS, MapReduce, and Yarn in Hadoop, as well as other procedures to comprehend how it functions.
What is Hadoop?
Let's review the fundamental Hadoop notion first before learning how it functions. A group of free and open-source software tools is called Apache Hadoop. They enable the use of a vast computer network to efficiently tackle issues requiring enormous volumes of data. It offers a software architecture for distributed computing and storage. It splits a file into the specified number of blocks and spreads them among a group of computers. By repeating the blocks on the cluster, Hadoop also provides fault tolerance. By breaking out a work into a number of separate jobs, it does distributed processing. Over the computer cluster, these operations take place in parallel.
Hadoop Components and Domains
Hadoop's fundamental components must be understood in order to comprehend how it functions. Hadoop thus has three levels (or main components), and they are as follows:
Hadoop is stored using HDFS, or Hadoop Distributed File System. It stores the data in a scattered fashion, as the name would imply. The file is broken into a number of chunks and distributed throughout the commodity hardware cluster.
Hadoop's processing engine is called MapReduce. The distributed processing theory underlies MapReduce's operation. It separates the user-submitted job into a number of separate subtasks. The throughput is increased by the concurrent execution of these subtasks.
Hadoop's resource management is handled by Yarn - Yet Another Resource Manager. Two daemons are searching for Yarn. On the slave computers, one is the NodeManager, while on the master node, the other is the Resource Manager. Yarn is in charge of managing how the resources are distributed among the different slaves vying for them.
The background-running processes are known as daemons. These are the Hadoop Daemons:
a) Namenode – It functions on the HDFS master node.
b) Datanode – It functions on HDFS slave nodes.
c) Resource Manager – It functions on the MapReduce YARN master node.
d) Node Manager – It operates on the MapReduce slave node of YARN.
For Hadoop to work, these 4 daemons must be running.
How Hadoop Works?
Hadoop operates on numerous computers at once and distributes processing for massive data sets across the cluster of commodity servers. The client sends data and a program to Hadoop for processing any data. While MapReduce processes the data and Yarn divides the jobs, HDFS stores the data.
Let's examine Hadoop's operation in more depth.
HDFS
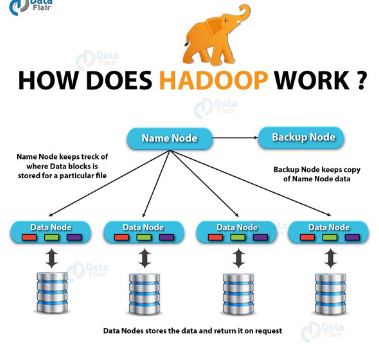
In the Hadoop Distributed File System, the topology is master-slave. NameNode and DataNode are the two daemons that are now executing on it.
NameNode
The daemon executing on the master computer is called NameNode. The core of an HDFS file system is it. All of the file system's directory trees are stored in NameNodes. It keeps track of where the file data is located inside the cluster. The information present in these files is not stored there.
Client programs communicate with NameNode when they want to add, copy, move, or delete a file. A list of pertinent DataNode servers housing the data is returned by the NameNode in response to the client's request.
DataNode
On the slave nodes, the DataNode daemon is active. The HadoopFileSystem is used to store the data. Data replication occurs across numerous DataNodes in a working file system.
A DataNode connects to the NameNode when it first starts. It never stops looking for the data access request from NameNode. Client applications can communicate directly with a DataNode after the NameNode specifies the data's location, and DataNode instances can communicate with one another as they replicate the data.
Replica Placement
Performance and dependability of HDFS are determined by where the replica is placed. The arrangement of replicas has been optimized, setting HDFS apart from other distributed systems. Large HDFS instances are operated by a cluster of machines arranged in numerous racks. The switches are required for inter-rack communication between nodes. The network bandwidth between nodes in a single rack is typically greater than that between machines in different racks.
Each DataNode's rack id is determined by the rack awareness algorithm. The replicas are arranged on separate racks according to a straightforward policy. In the event of rack failure, this prevents data loss. Additionally, while reading data, it uses bandwidth from several racks. However, using this approach raises the price of writing.
Assume that there are three replication factors. Let's say that according to HDFS's placement policy, two replicas are located remotely on the same rack while one replica is local. By reducing inter-rack write traffic, this policy enhances write performance. The likelihood of a rack failing is lower than that of a node. As a result, this regulation has no impact on the availability and dependability of data. However, it does lessen the overall network bandwidth consumed for data reading. This is due to the fact that a block is placed in two distinct racks as opposed to three.
MapReduce
The MapReduce algorithm's general concept is to process the data on your distributed cluster in parallel. It then combines it to create the final product or output.
Hadoop MapReduce has the following stages:
- The program locates and reads the "input file" holding the raw data in the first stage.
- Data must be transformed into a format that the application can understand because the file format is arbitrary. This is done by the "InputFormat" and the "RecordReader" (RR).
The file is divided into smaller sections by the input format using the input split function.
The raw data is then transformed by the RecordReader so that the map can process it. A list of key-value pairs is the result.
These key-value pairs are processed by the mapper, and the outcome is sent to a "OutputCollector." Another feature called "Reporter" notifies the user when the mapping operation is complete.
- The Reduce function then does its work to each key-value pair from the mapper in the following phase.
- The key-value pairs from Reducer are organized by OutputFormat before being written to HDFS.
- Map-Reduce, the brains behind Hadoop, processes data in a fault-tolerant, highly robust manner.
Yarn
Yarn creates distinct daemons to handle the tasks of resource management and job scheduling and monitoring. Each application has a separate ApplicationMaster and ResourceManager. A job or a DAG of jobs can both be included in an application.
The Scheduler and ApplicationManager are the two parts of the ResourceManger.
The scheduler does not monitor the status of running apps because it is a pure scheduler. It only distributes resources to various programs that are rivals. Additionally, it does not restart the job after a hardware or software failure. An abstract idea of a container serves as the basis for the scheduler's resource allocation. A container is merely a portion of several resources, including CPU, memory, disk, and network.
The duties of ApplicationManager are as follows:-
- accepts job submissions from clients.
- initial container is negotiated for a particular ApplicationMaster.
- following an unsuccessful application, restarts the container.
The obligations of ApplicationMaster are listed below.
- scheduler's containers in negotiations
- tracking the state of the container and following its development.
The idea of Resource Reservation via ReservationSystem is supported by Yarn. This allows the user to set up various resources for the execution of a specific task under time and temporal limits. Resources are made sure to be available for the work till it is finished by the ReservationSystem. It also handles reservation-related admission control.
Through the Yarn Federation, Yarn may scale beyond a few thousand nodes. Multiple sub-clusters can be combined into a single large cluster using YARN Federation. For a single big job, we can use a lot of independent clusters working together. It can be applied to create an expansive system.
Here is a step-by-step breakdown of how Hadoop functions:
- The input data is divided into 128 Mb blocks, and the blocks are subsequently transported to various nodes.
- The user can process the data once all of the data's blocks have been stored on data-nodes.
- The user-submitted software is subsequently scheduled by the resource manager on each individual node.
- The output is written back to HDFS when the data has been processed by all of the nodes.
This concludes the tutorial on how Hadoop functions.
Conclusion
To summarize How Hadoop Works, we may say that the client provides the software and data first. That data is processed by MapReduce and stored in HDFS. In order to advance in the technology, let's learn how to install Hadoop on a single node and multi-node now that we have learned about its introduction and how it functions.
If you have any questions or comments on "How Hadoop Works," leave a comment and we'll get back to you.
