Azure Data Lake and Azure NoSQL
- Neng Ilha
- 2022 November 14T12:37
- Azure Big Data
Describe Azure Data Lake.
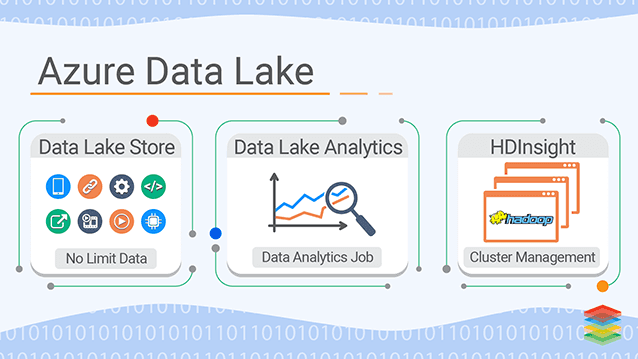
The Microsoft Azure ecosystem's many cloud services provide the foundation of the big data solution known as Azure Data Lake. It enables storage, processing, and analytics by allowing enterprises to ingest various data sources, including structured, unstructured, and semi-structured data.
You may process, query, and analyze data using Spark, MapReduce, SQL querying, NoSQL data models, and other analytics capabilities that Azure offers. We'll concentrate on four essential elements: HDInsights, Azure Data Lake Storage (ADLS), Azure Data Lake Analytics (ADLA), and core data lake architecture.
4 Data Lake Building Blocks on Azure
In Azure, a data lake solution generally consists of four components. Azure's basic infrastructure, which includes blob storage, Azure Data Factory, and Hadoop YARN, serves as the foundation for all data lakes.
In addition, businesses have the option to employ Azure Data Lake Analytics, a computer service that analyses massive data sets using T-SQL, and Azure Data Lake Storage, a dedicated storage solution for large-scale datasets. Azure HDInsight, another optional component, enables you to conduct distributed big data workloads using programs like Hadoop and Spark.
Core Infrastructure
Azure Blob Storage, an elastic object storage solution with low-cost tiered storage, high availability, and powerful disaster recovery features, is the foundation of Azure Data Lake.
Blob Storage and Azure Data Factory, a tool for developing and performing extract, transform, load (ETL), and extract, load and transform (ELT) operations, are integrated as part of the solution. In order to control the scalability of SQL Server instances, Azure SQL Database instances, and Azure SQL Data Warehouse servers, it also employs the Apache Hadoop YARN cluster management framework.
Azure Data Lake Storage (ADLS)
Massive datasets may be kept in Azure Data Lake Storage, a repository. It offers two options for data storage:
- WebHDFS storage—ccompatible with the Hadoop File System (HDFS), a highly secure hierarchical data storage.
- Data lake blob storage—With the full capabilities of Azure Blob Storage, including encryption, data tiering, connectivity with Azure AD, and data lifecycle management, you can store data as blobs.
Azure Data Lake Analytics (ADLA)
You may connect to and process data from ADLS using the computing service known as Azure Data Lake Analytics. It gives.NET developers a platform to efficiently process up to petabytes of data. Users may conduct analytics jobs of any size with Azure Data Lake Analytics by utilizing U-SQL to carry out C# and SQL-based analytics operations.
Azure HDInsight
Running distributed large data workloads on Azure infrastructure is made possible by Azure HDInsight, a managed service. Popular open source frameworks like Apache Hadoop, Spark, and Kafka may all be used by users. Without the requirement for installation or customization, it enables you to take advantage of these open source projects with fully managed infrastructure and cluster administration.
Creating Your Azure Data Lake: Associated Services
The primary Azure services you may utilize to create your data lake architecture are listed in the following table.
|
Service |
Description |
How a Data Lake works |
|
Azure Blob Storage |
Object management storage |
Keeping unstructured information |
|
Azure Databricks |
Azure Spark-based serverless analytics |
processing of huge files in batches |
|
Cosmos DB |
manageable NoSQL data storage that supports Cassandra and MongoDB |
Key-value pairs are stored without a set structure. |
|
Azure SQL Database |
SQL Server controlled via the cloud |
Using SQL queries to store relational datasets |
|
Azure SQL Datawarehouse |
corporate data warehouse on the cloud (EDW) |
preserving vast amounts of structured data and allowing highly parallel processing (MPP) |
|
Azure Analysis Service |
SQL Server Analysis Server-based analytics engine |
Ad-hoc semantic model construction for tabular data |
|
Azure Data Factory |
ETL service on the cloud |
Including the data lake with more than 50 databases and storage systems, and data transformation |
Top Techniques for Azure Data Lake
Here are a few best practices to follow so you can get the most out of your Azure data lake implementation.
Security
Access control through the Portable Operating System Interface (POSIX) is offered by Azure Data Lake Storage Gen2 for users, groups, and service principals established in Azure Active Directory (Azure AD). On already-existing files and folders, these access constraints can be configured. Create default permissions using access control so they may be automatically applied to new files or folders.
Resiliency
You must think about availability needs and potential service failures when developing a system that uses cloud or Data Lake Storage. Planning is necessary for outages that might effect a single computer instance, a zone, or an entire area.
Think about the goal recovery time objective (RTO) and recovery point objective (RPO) for the workload (RPO). Benefit from the variety of storage redundancy choices offered by Azure, including Local Redundant Storage (LRS) and Read-Access Geo-Redundant Storage (RA-GRS).
Directory Layout
You should design your data structure to provide security, effective processing, and partitioning when ingesting data into a data lake. Consider factors like organizational unit, data source, timescale, and processing needs while planning the directory structure.
In most circumstances, you should start your directory structure with the region and conclude it with the date. This enables you to restrict access to particular users or areas of data using POSIX permissions. By placing the date at the end, you may restrict particular date ranges without needing to process several subdirectories.
Cloud Volumes ONTAP from NetApp and Azure Data Lake
The top enterprise-grade storage management solution, NetApp Cloud Volumes ONTAP, offers safe, tried-and-true storage management services on AWS, Azure, and Google Cloud. With a powerful set of capabilities like high availability, data security, storage efficiency, Kubernetes integration, and more, Cloud Volumes ONTAP supports up to a capacity of 368TB and diverse use cases including file services, databases, DevOps, or any other corporate application.
Advanced functionality for managing SAN storage in the cloud, accommodating NoSQL database systems, as well as NFS shares that can be directly accessible from cloud big data analytics clusters are supported by Cloud Volumes ONTAP.
Additional storage efficiency capabilities offered by Cloud Volumes ONTAP include thin provisioning, data compression, and deduplication, which may save prices and footprint of storage by up to 70%.
What is Azure NoSQL?
NoSQL databases are those that use data models other than relational tables as their foundation. NoSQL databases can be of the key-value, document, graph, or wide-column kind. These databases are getting more and more common as businesses produce bigger amounts and more diverse unstructured data.
There are several NoSQL database solutions and numerous hosting or deployment options in Microsoft Azure. MongoDB, Gremlin, and Cassandra are some of the NoSQL big data options provided by Azure.
Different Azure NoSQL Database Types
Key-value, document, columnar, and graph NoSQL databases are the four categories of NoSQL databases that Azure offers choices for. The differences between these databases and the services that each kind is provided by Azure are explained below.
Key-Value
Hash tables are used by key-value databases to hold paired keys and values. With the help of these tools, you may provide certain keys data values and afterwards get the data using the key. You can store as many values as you like in a key-value database. Applications linked to the database deliver and understand data schemas.
Key-value databases can be used for applications that do straightforward lookups. However, keep in mind that a key-value database is less suited to data searching and is not intended for value queries. Key-value databases' scalability, which is often the consequence of simple data distribution over several nodes on different computers, is its major benefit.
Key-value databases have the following major use cases:
- Session management
- Data caching
- Product recommendation
- User preferences
- Serving ads
- Profile management
Azure's selection of key-value databases: Cosmos DB controlled service using Cassandra
Document
Similar to key-value databases, document databases hold whole documents organised in groups or collections as opposed to individual values. You can query these documents' key-value pairs to get information. JSON, YAML, and XML are just a few of the formats that may be used to store documents. Each document in these databases may have a unique structure.
Documents can include a variety of data kinds, and they can be organized using a variety of different formats. However, you must make sure that each document only contains information about a single entity, such as a client or an order. It is feasible to spread data from a single document over several relational tables in your RDBMS.
Key instances of document databases' use are as follows:
- Content management
- Product catalog
- Inventory management
Azure offers MongoDB through the Cosmos DB managed service as a document database.
Columnar
You may store data in table format using a columnar database, sometimes referred to as a column-family or wide-column database. These databases, as opposed to relational databases, use a denormalized approach to sparse data. Due to the fact that not all tables or rows must contain the same data, you can store numerous tables within a database.
The majority of column-family databases store data in key order, in contrast to key-value databases and document databases, which store data using a computational hash. Typically, you may define indexes for particular columns within a column-family using columnar implementations. Then, instead of utilizing row keys to access data, indexes may be used to access data.
Read and write operations for a row in columnar databases are frequently atomic with a single column-family. Although this is not always the case, certain databases may offer atomicity for several column families over the whole row.
The following are important use cases for columnar databases:
- Telemetry
- Messaging
- Recommendations
- Activity monitoring
- Personalization
- Social media analytics
- Sensor data
- Weather and other time-series data
- Web analytics
Columnar database offered on Azure: Azure Table Storage
Graph
Graph databases use nodes and edges to map the connections between the data. Data values are nodes, whereas interactions between these nodes and values—which may also be directional—are edges. These databases are made to display hierarchical or intricately connected data structures.
Graph databases can run queries on a network of nodes and edges and examine the connections between the nodes and edges. Large networks with plenty of items and connections may carry out extremely sophisticated analysis fast. Furthermore, graph databases frequently include a query language that makes it simple to switch between relationship networks.
The following are important use cases for graph databases:
- Fraud detection
- Social graphs
- Recommendation engines
- Organization charts
Graph database offered on Azure: Gremlin (via Cosmos managed service)
A Cosmos DB-powered Azure NoSQL Managed Database
Cosmos DB is the NoSQL service Microsoft Azure provides that is the most capable. This managed service offers APIs and engines for several database types. Transparent multi-master replication, turnkey worldwide distribution, intelligent scalability, and a variety of consistency choices are among the characteristics offered by Cosmos DB. The main option is Cosmos DB, although there are variants available through API, including choices for
Gremlin API in Azure Cosmos DB
A graph computing framework called the Gremlin API is built on Apache TinkerPop. It has automated graph partitioning, automatic indexing, and allows you to elastically scale your database. You can run real-time queries using this API without defining views, secondary indexes, or schema hints because it employs the Gremlin syntax.
MongoDB API in Azure Cosmos DB
The wire protocol of the database is applied to Cosmos DB through the MongoDB API. You can use native MongoDB tools, drivers, and client SDKs because of this. With the help of this API, you may migrate current apps with few changes while ensuring their vendor independence.
Table API in Azure Cosmos DB
With the help of the Table API interface, you can add Cosmos DB functionality to applications created for Azure Table Storage. For instance, dedicated global throughput and millisecond latencies in the single digits. You may move apps using this API without changing the code. This API comes with client SDKs for Java,.NET, Python, Node.js, and Python.
Azure Cosmos DB Cassandra API
You may connect to already-running Cassandra apps and get data using the Cassandra Query Language (CQL) thanks to the Cassandra API. Additionally, this API offers functionality for numerous consistency levels, compliance certifications, and permanent change tracking.
