Hadoop Architecture in Detail
- Mister siswa
- 2022 November 27T17:02
- Hadoop
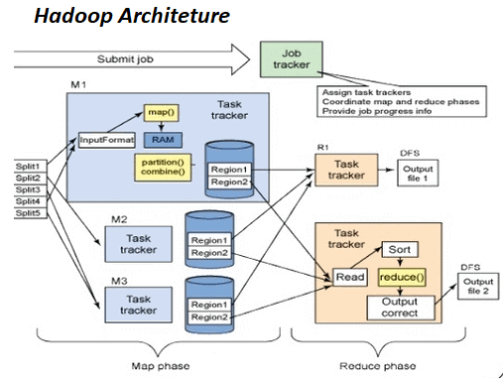
Today, Hadoop is a well-liked answer to the problems of the modern world. Hadoop was created with a number of objectives in mind. These include data localization, management of huge datasets, fault tolerance, and portability across many hardware and software platforms, among others. We shall thoroughly examine the Hadoop Architecture in this blog. In order to help you comprehend it better, we will also show you the Hadoop Architecture Diagram.
Let's investigate Hadoop Architecture now.
What is Hadoop Architecture?
A master-slave topology governs Hadoop. We have a single master node and numerous slave nodes in this design. The role of the master node is to allocate tasks to different slave nodes and manage resources. The actual computing is done by the slave nodes. While master nodes include metadata, slave nodes hold the actual data. Thus, it keeps information on information. We'll examine what metadata consists of in a moment.
Detail of Hadoop Application Architecture
There are three main layers in the Hadoop architecture. They include:
- HDFS (Hadoop Distributed File System)
- Yarn
- MapReduce
1. HDFS
Hadoop Distributed File System is known as HDFS. Hadoop's data storage is made possible by it. The data unit is divided into smaller parts, known as blocks, and stored using a distributed storage system (HDFS). It is running two daemons. NameNode is used for master nodes, and DataNode is used for slave nodes.
NameNode and DataNode
A master-slave architecture underlies HDFS. On the master server, the daemon known as NameNode is active. It controls client file access and is in charge of managing namespaces. Slave nodes are used by the DataNode daemon. It is in charge of keeping real business data. A file is internally divided into several data blocks and stored on a number of slave devices. The file system namespace is managed by namenode. The opening, shutting, and renaming of files or directories are examples of these actions. The mapping of blocks to DataNodes is also kept care of by NameNode. This DataNode responds to read and write requests from clients using the file system. Additionally, DataNode duplicates, deletes, and creates blocks from NameNode as needed.
The native language of HDFS is Java. Therefore, Java-enabled machines can deploy DataNode and NameNode. In a typical deployment, NameNode is run on a single dedicated machine. And DataNode is used by every other node in the cluster. Block locations on the DataNodes and other metadata are contained in the NameNode. And decides how to distribute resources across many rival DataNodes.
Block in HDFS
The smallest type of storage on a computer system is called a block. It is the least amount of contiguous storage that has been given to a file. The default block size in Hadoop is 128MB or 256MB.
The block size should be carefully chosen. Let's use the example of a file that is 700 MB in size to illustrate why. HDFS distributes the file into 6 blocks if our block size is 128MB. One block of 60MB and five blocks of 128MB are used. What will occur if the block is 4 KB in size? However, HDFS would include files that ranged in size from terabytes to petabytes. We would have many blocks if the block size were 4 KB. As a result, the NameNode will get overloaded with a large amount of metadata. As a result, we must choose our HDFS block size carefully.
Replication Management
HDFS employs a replication mechanism to achieve fault tolerance. It does this by making copies of the blocks and storing them on various DataNodes. How many copies of the blocks are saved depends on the replication factor. By default, it is set to 3, but we can modify it to any value.
The replication technique's operation is depicted in the above figure. With a replication ratio of 3, a file that is 1 GB in size will require 3 GBs of total storage.
Every DataNode's block report is gathered by NameNode in order to maintain the replication factor. The NameNode adds or removes replicas in accordance with whether a block is under- or over-replicated.
What is Rack Awareness?
Numerous DataNode units are housed on a rack, which is used in manufacturing. The replicas of the blocks are distributed using the rack awareness mechanism of HDFS. Low latency and fault tolerance are provided by this rack awareness method. Let's say the preset replication factor is 3. Now, a local rack will receive the first block thanks to the rack awareness algorithm. The other two blocks will remain on a different rack. If possible, it doesn't hold more than two blocks in a single rack.
2. MapReduce
The Hadoop data processing layer is called MapReduce. It's a software framework that makes it possible to create programs for handling massive amounts of data. These programs are executed simultaneously by MapReduce on a group of low-end computers. It accomplishes this in a trustworthy and fault-tolerant way.
Numerous map jobs and reduce tasks make up a map-reduce job. Each operation utilizes a certain portion of the data. The burden is divided among the cluster as a result. Data is loaded, parsed, transformed, and filtered by Map tasks. The output from the map tasks' subset is used by each reduction task. This intermediate data from the map tasks is subjected to grouping and aggregation by the reduce process.
The MapReduce job's input file is already present on HDFS. How the input file is divided into input splits is determined by the inputformat. Simply described, input split is a byte-oriented view of the relevant input file portion. The map job loads up this input split. The node that has the pertinent data is where the map job is executed. The data can be processed locally without traveling over a network.
Map Task
The phases of the Map job are as follows:-
RecordReader
The input split is converted into records by the recordreader. It does not parse records itself; rather, it parses the data into records. Key-value pairs are used to deliver the data to the mapper function. Typically, the positional information is the key, and the data that makes up the record is its value.
Map
Here, the key-value pair from the recordreader is processed by the mapper, a user-defined function. It generates a single intermediate key-value pair or more.
The mapper function determines what will be the key-value pair. The data that the reducer function uses to perform the grouping action is often the key. Value is the data that the reducer function aggregates to produce the final output.
Combiner
The data are grouped in the map phase by the combiner, which is essentially a localized reducer. It's not required. The mapper's intermediate data are aggregated by the combiner. It operates in the constrained range of a single mapper. This frequently reduces the amount of data that must be transferred across the network. Changing (Hello World, 1) three times, for instance, uses more network capacity than changing (Hello World, 3). Combiners have no disadvantages and offer extremely high performance gains. It is not a given that the combiner will operate. As a result, it is not an algorithm overall.
Partitioner
The intermediate key-value pairs are taken from the mapper by the partitioner. They are divided into shards, one shard for each reducer. Partitioner retrieves the key's hashcode by default. The partitioner uses several reducers to carry out modulus operations: key.hashcode()% (number of reducers). This equally splits the keyspace across the reducers. Additionally, it guarantees that keys with identical values but coming from various mappers end up in the same reducer. Each map task writes the partitioned data to the local file system. In order for the reducer to pull it, it waits there.
Reduce Task
These are the different stages of the reduction task:
Shuffle and Sort
The shuffle and sort phase comes first in the reduction. In this stage, the data that the partitioner wrote is downloaded to the computer executing the reduction. The individual data components are sorted into a lengthy data list in this step. This sort's objective is to compile all of the equivalent keys. The framework implements this so that the reduction job can simply iterate over it. This stage cannot be changed. Using a framework, everything is done automatically. The keys' grouping and ordering, however, are under the developer's control thanks to a comparator object.
Reduce
Per key grouping, the reducer executes the reduce function once. The function key and an iterator object containing all the key-related values are sent by the framework.
Reducers can be created to filter, integrate, and aggregate data in a variety of ways. The outputformat receives zero or more key-value pairs once the reduce function is complete. Reduce function varies depending on the task, much like map function. Because it forms the basis of the answer.
OutputFormat
This is the last action. The recordwriter reads the key-value pair from the reducer and writes it to the file. By default, it uses tabs to divide the key and value and newlines to separate each entry. To provide a richer output format, we can tweak it. However, final data is still written to HDFS.
3. YARN
The resource management layer of Hadoop is referred known as YARN, or Yet Another Resource Negotiator. The fundamental idea underlying YARN is to divide the tasks of managing resources and scheduling and monitoring jobs into distinct daemons. There is a single global ResourceManager and an ApplicationMaster for each application in YARN. A DAG of jobs or a single task can both constitute an application.
The ResourceManager and NodeManager daemons are two components of the YARN system. The ResourceManager arbitrates the distribution of resources among all the system's contending applications. Monitoring the resource utilization by the container and reporting it to ResourceManger is the responsibility of NodeManger. The resources include things like the network, CPU, RAM, and disk.
In order to run and monitor the job, the ApplicationMaster collaborates with NodeManager to negotiate resources with ResourceManager.
Scheduler and ApplicationManager are two significant components of the ResourceManger.
Scheduler
Resources are distributed to various programs via the scheduler. Since it doesn't track the application's status, this is a pure scheduler. Additionally, it does not reschedule tasks that fail as a result of hardware or software issues. In accordance with the needs of the applications, the scheduler distributes the resources.
Application Manager
The following are some of ApplicationManager's features.
- takes job applications.
- chooses the first container for the ApplicationMaster to run in. In a container, components like CPU, memory, disk, and network are all included.
- Upon failure, restarts the ApplicationMaster container.
ApplicationMaster's features include:
- asks Scheduler for a resource container in negotiations.
- monitors the status of the resource container.
- keeps track of the application's development.
Through the YARN Federation functionality, we can scale the YARN beyond a few thousand nodes. We can connect various YARN clusters into a single enormous cluster using this functionality. This enables the use of separate clusters that are combined for a very large operation.
Features of Yarn
The following characteristics of YARN:-
a. Multi-tenancy
On the same Hadoop data collection, YARN offers a variety of access engines (proprietary or open-source). These access engines can handle data in batches, in real time, iteratively, and other ways.
b. Cluster Utilization
The dynamic resource allocation provided by YARN enables efficient cluster utilization. compared to static map-reduce rules in earlier Hadoop versions, which offer lower cluster usage.
c. Scalability
Any data center's processing capacity is constantly growing. Petabytes of data are processed by YARN's ResourceManager, which focuses on scheduling and manages the constantly growing cluster.
d. Compatibility
Programs like MapReduce created for Hadoop 1.x can still run on this YARN. And all of this has occurred without altering any currently efficient processes.
Guidelines For Designing A Hadoop Architecture
Adopt Redundancy and Use Common Hardware
Many businesses use Hadoop for their business users or analytics teams. Later come the infrastructure professionals. These people frequently have no knowledge of Hadoop. The over-sized cluster that results greatly expands the budget. Hadoop was primarily developed to provide inexpensive storage and in-depth data analysis. Use JBOD, short for Just a Bunch of Disks, to do this. Use just one power source as well.
Start Little and Remain Focused
Due to their expenditure and complexity, many projects end in failure. Start with a modest cluster of nodes and build more as you go to prevent this. Start with a tiny project to let the infrastructure and development staff members better grasp how Hadoop functions internally.
Make a Process For Integrating Data
One of Hadoop's advantages is the ability to dump the data first. The data structure can be defined later. With the help of tools like Flume and Sqoop, we can simply obtain data. But developing a data integration method is crucial. This covers a number of layers, including staging, naming conventions, location, etc. Make sure to properly document the sources of the data and their locations inside the cluster.
Utilize the compression technique
Compression and Enterprise have a love-hate relationship. Storage and performance can be compromised. Although compression reduces the amount of storage used, it also lowers performance. Hadoop, meanwhile, thrives on compression. It can use up to 80% more storage.
Make Several Environments
Building several environments for development, testing, and production is a best practice. Since Apache Hadoop has a large ecosystem, many projects inside it have various needs. Therefore, a non-production environment is required for testing updates and new features.
Summary
As a result, we noticed that the Hadoop Architecture is designed in such a way that it can self-recovery when necessary in this Hadoop Application Architecture. It is resilient and fault-tolerant due to the redundant storage structure. The system can be scaled linearly. The MapReduce component of the design relies on the locality of data. With the Map-Reduce framework, computing is brought near to the data. reducing network traffic that would have otherwise used a lot of capacity to move massive datasets. Hadoop's entire architecture thus makes big data technology affordable, scalable, and effective.
The subject of Hadoop Architecture is crucial for your Hadoop interview. We advise you to look over the frequently asked Hadoop Interview questions once. Hadoop Architecture will ask you several questions.
