Hadoop
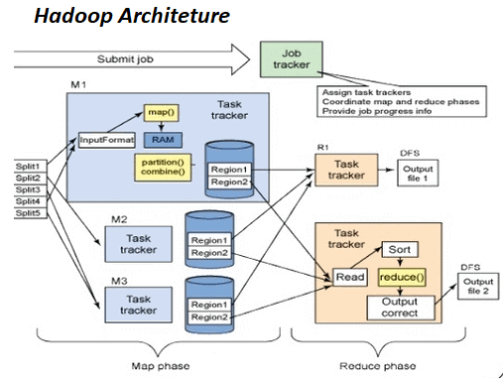
Hadoop Architecture in Detail
- Mister siswa
- 2022 November 27 17:02
- Hadoop
Today, Hadoop is a well-liked answer to the problems of the modern world. Hadoop was created with a number of objectives in mind. These include data localization, management of huge datasets, fault tolerance, and portability across many hardware and software platforms, among others. We shall thoroughly examine the Hadoop Architecture in this blog. In order to help you comprehend it better, we will also show you the Hadoop Architecture Diagram.
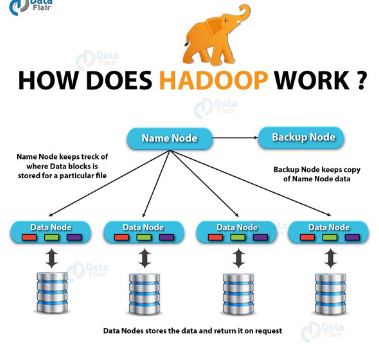
How Hadoop Works Internally
- Mister siswa
- 2022 November 25 10:04
- Hadoop
An open source software platform called Apache Hadoop stores data in a distributed fashion and processes it concurrently. Hadoop offers the most dependable batch processing engine, MapReduce, as well as the most trustworthy storage layer, HDFS, and resource management layer, YARN. In this lesson on "How Hadoop works internally," we will learn what Hadoop is, how it functions, its many parts, daemons, the functions of HDFS, MapReduce, and Yarn in Hadoop, as well as other procedures to comprehend how it functions.

Apache Hadoop vs Apache Spark
- Mister siswa
- 2022 November 21 13:41
- Hadoop
Hadoop and Spark are two well-known big data technologies that were developed by the Apache Software Foundation. In order to handle, manage, and analyze enormous volumes of data, each framework has access to a robust ecosystem of open-source tools.

What is Hadoop?
- Kang siswa
- 2022 November 19 11:21
- Hadoop
For storing and analyzing large amounts of data, Hadoop is an open source framework built on Java. The information is kept on low-cost, clustered commodity servers. Its distributed file system supports fault tolerance and parallel processing. Hadoop, created by Doug Cutting and Michael J. Cafarella, stores and retrieves data from its nodes more quickly using the MapReduce programming style. The Apache License 2.0 governs the use of the framework, which is overseen by the Apache Software Foundation.
Recent Posts
- 5 Comprehensive Aspects Big Data Aws
- Aws Services Every Data Scientist Uses
- Centrally Managed Aws Backup For Amazon Cloud
- Guide To Doing Big Data With Aws
- Understand Aws Big Data And Solutions
- Azure Analytics Services And Azure Hdinsight
- Azure Big Data Steps To Building Your Solution
- Azure Data Lake And Azure Nosql
- Azure Hdinsight Best Practices
- Big Data Analytics
- Big Data Technologies
- The Role Of Big Data In Banking
- What Is Big Data
- Apache Hadoop Vs Apache Spark
- Hadoop Architecture In Detail
- How Hadoop Works Internally
- What Is Hadoop
